
Rethinking tools so we can dream a little
domain specific environments > domain specific models

Let’s say that there is a dataset with numbers related to smoking, age and health outcome. Given such a dataset, you might be interested in running some queries. You could use SQL to describe what you want, but if you've taken a course in probability theory then you might write this on a piece of paper instead.
I know this is going down the “probability nerd snipe” territory, but I was wondering how close I could get a Python API to this notation. After all, this is *very* compact compared to any SQL that you might write.
Enter peegeem
I wrote a small library in Python that allows for *exactly* this. Not only does it give you the fancy notation, you're also able to declare the probabilistic graphical model that outlines the causal relationships between your variables.
from peegeem import DAG
# Define the DAG for the PGM, nodes is a list of column names, edges is a list of tuples
dag = DAG(nodes, edges, dataframe)
# Get variables out
outcome, smoker, age = dag.get_variables()
# Use variables to construct a probabilistic query
P(outcome | (smoker == "Yes") & (age > 40))
# Latex utility, why not?
P.to_latex(outcome | (smoker == "Yes") & (age > 40))It's pretty darn neat! It's really like writing down maths and you get a data-list out with all relevant probability values. But want to know the real kicker? You can use this in a notebook together with some widgets!
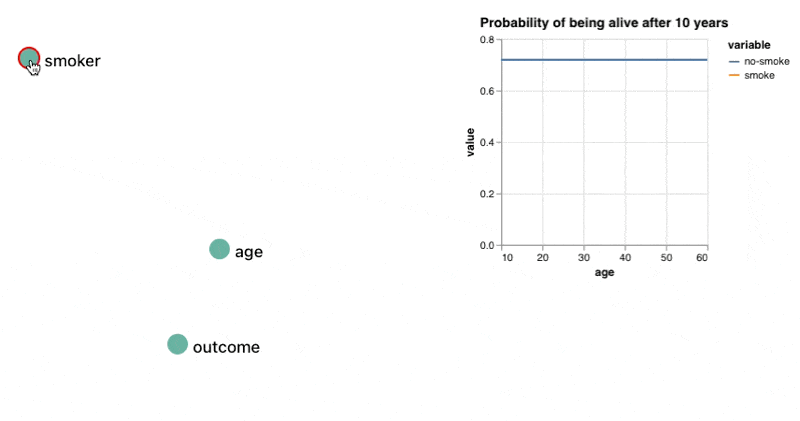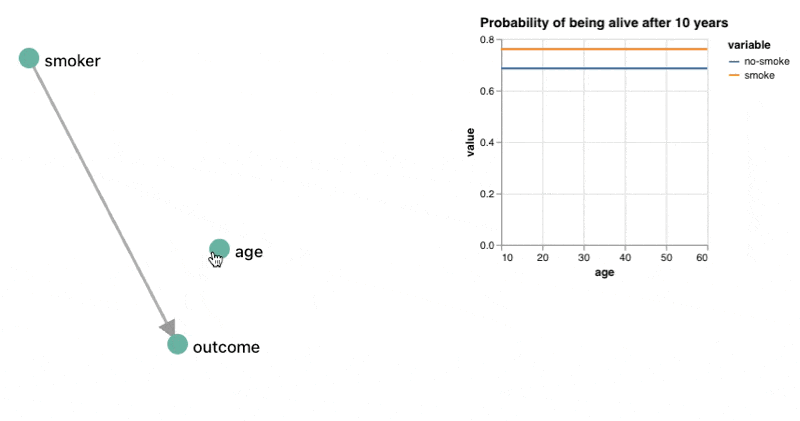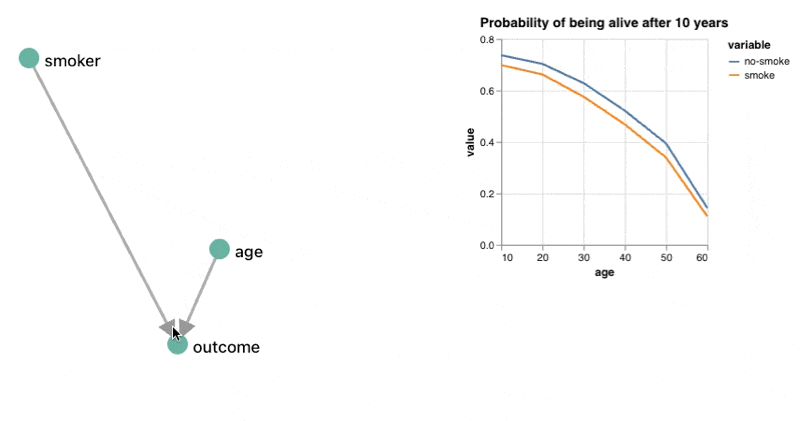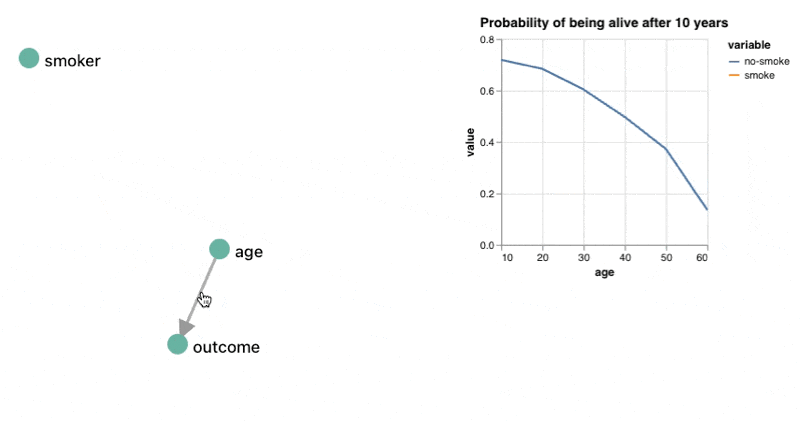
Again, it helps to be a probability nerd here, but one clever thing we can do is combine our query ability with the ability to use reactive components and charts. By doing this, you kind of get a domain specific environment instead of just a domain specific language to interface with.
This is super exciting and I hope to work on more projects like this one. If you're keen to learn more, and see an extensive demo, you might enjoy this marimo livestream that I did for it last week.